
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- knn분류기
- R Studio
- 상자그림
- 파티셔닝
- 글또
- partitioning
- axios
- f45
- 데이터베이스 인덱스
- 복합인덱스
- 데이터베이스 파티셔닝
- 레디스
- k-Nearest Neighbors
- axis interceptor
- System Design
- 다섯수치요약
- 데이터베이스
- Sharding
- 머신러닝
- DB 파티셔닝
- 오버라이딩
- LRU
- 가상면접 사례로 배우는 대규모 시스템 설계
- 쿼리 실행계획
- redis
- 인덱스 추가
- Retry
- 인덱스 순서
- 통계학개론
- 샤딩
- Today
- Total
haileyjpark
[데이터베이스] 파티셔닝과 샤딩의 이해 본문
🌳 파티셔닝이란?
Oracle V8.0에서 도입.
논리적인 데이터 element들을 다수의 entity로 쪼개는 행위를 뜻하는 일반적인 용어.
즉, 큰 table이나 index를, 관리하기 쉬운 partition이라는 작은 단위로 물리적으로 분할하는 것을 의미한다.
물리적인 데이터 분할이 있더라도, DB에 접근하는 application의 입장에서는 이를 인식하지 못한다.
🌳 등장 배경
서비스의 크기가 점점 커지고 DB에 저장하는 데이터의 규모 또한 대용량화 되면서, 기존에 사용하는 DB 시스템의 용량(storage)의 한계와 성능(performance)의 저하를 가져오게 되었다.
즉, VLDB(Very Large DBMS)와 같이 하나의 DBMS에 너무 큰 table이 들어가면서 용량과 성능 측면에서 많은 이슈가 발생하게 되었고, 이런 이슈를 해결하기 위한 방법으로 table을 파티션(partition)이라는 작은 단위로 나누어서 관리하는 파티셔닝 기법이 나타나게 되었다.
파티셔닝 기법을 통해 소프트웨어적으로 데이터베이스를 분산 처리하여 성능이 저하되는 것을 방지하고 관리를 보다 수월하게 할 수 있게 되었다.
🌳 파티셔닝 사용의 이점
가용성(Availability)
- 물리적인 파티셔닝으로 인해 전체 데이터의 훼손 가능성이 줄어들고 데이터 가용성이 향상된다.
- 각 분할 영역(파티션)을 독립적으로 백업하고 복구할 수 있다.
관리용이성(Manageability)
- 데이터베이스의 큰 객체(테이블)들을 제거하여 관리를 쉽게 해줌
성능(Performance)
- 특정 DML과 Query의 성능을 향상시킴. 주로 대용량 Date WRITE 환경에서 효율적이다.
- 필요한 데이터만 빠르게 조회할 수 있기 때문에 쿼리 자체가 가볍다.
- 특히, Full Scan에서 데이터 Access의 범위를 줄여 성능 향상을 가져온다.
- 많은 INSERT가 있는 OLTP 시스템에서 INSERT 작업을 작은 단위인 파티션들로 분산시켜 경합을 줄인다.
- 테이블의 파티션 단위로 Disk I/O를 분산하여 경합을 줄이기 때문에 UPDATE 성능을 향상시킨다.
OLTP란?
- OLTP는 Oline Transation Processing의 줄임말로 트랜잭션 데이터를 관리하는 방식을 말한다.
- 일반적으로 회사에서 기본적으로 사용하고 있는 ERP와 같은 시스템의 처리 방식.
- OLTP 방식을 사용하는 경우는 하루에도 대량으로 처리되는 업무상의 트랜잭션을 처리하고 저장할 필요가 있는 경우에 사용. 빠르고 정확하게 처리되어야 하는 업무의 특성상 데이터를 처리하는 과정 속에서 딜레이가 발생하면 안되기 때문에 OLTP 환경은 빠른 처리 속도를 구현할 수 있는 아키텍처와 구성을 따라야 함.
- OLTP ↔ OLAP (참고 블로그 - OLAP)
- OLAP(Online Analytical Processing)은 대용량 업무 데이터베이스를 구성하고 BI(Business Intelligence)를 지원하기 위해 사용되는 기술
- 데이터 웨어하우스나 데이터 마트와 같은 대규모 데이터에 대해 최종 사용자가 정보에 직접 접근하여 대화식으로 정보를 분석하고 의사결정에 활용할 수 있는 실시간 분석처리
🌳 파티셔닝의 단점
- 테이블 간 JOIN에 대한 비용이 증가한다.
- 테이블과 인덱스를 별도로 파티셔닝할 수 없다. (테이블과 인덱스를 같이 파티셔닝해야 함)
- 데이터를 입력받았을 경우 어디에 넣어야 하는지에 대한 연산 오버헤드가 발생할 수 있 다
- 인덱스만으로도 해결되는 부분 파티셔닝을 무분별하게 파티셔닝을 적용했을 때는 오히려 성능이 나빠질 수 있음에 유의
→ 파티셔닝을 적용할 때는 적용하지 않았을 때와 비교해 확실한 성능의 이점이 생기는 지 꼭 확인 필요
🌳 파티셔닝이 적합한 경우
- 파티션 프루닝(partition pruning) : 검색 대상 파티션을 좁혀가는 동작
파티셔닝을 사용할지의 가장 큰 판단 기준은 파티션 프루닝을 할 수 있는 검색 조건을 포함한 쿼리의 실행 빈도이다.
파티션 프루닝이 유효한 쿼리가 대부분일 때는 파티셔닝에 의한 처리 전체의 효율화가 기대된다. (일반적으로 날짜를 기준으로 최신 데이터를 항상 참조할 경우)
그러나 파티셔닝이 적합하다고 판단될 때도 인덱스를 붙이는 것만으로 충분할 때가 대부분이다.
파티셔닝을 사용하는 이유는 단일 INSERT나 혹은 단일 Select, 범위 Select의 아주 빠른 처리가 필요할 경우 혹은 이력 데이터의 효율적인 관리가 필요한 경우이다. (불필요해진 데이터를 백업 & 삭제하는 작업이 상당히 고부하 작업이기 때문)
추가로 새로운 데이터를 차례로 추가하는 응용프로그램이며 과거의 데이터에 그다지 접근하지 않을 때는 레인지 파티셔닝을 수행해 엑세스되는 대상의 데이터 국소성을 최대한 활용할 수 있다. 파티셔닝을 사용하면 파티셔닝 별로 인덱스가 작성되기 때문이다.
최신 데이터가 항상 검색 대상이라면 하나의 파티션(마지막 파티션)만 액세스 대상이 될 것이고 액세스의 국소성이 있다면 캐시의 효율이 매우 향상된다. 따라서 대부분 검색이 메모리만으로 처리되고 디스크 I/O를 줄여서 성능 향상을 실현할 수 있다.
🌳 파티셔닝의 종류
1. 수평(horizontal) 파티셔닝

하나의 테이블의 각 행을 다른 테이블에 분산시키는 것이다.
개념
- 샤딩(Sharding)과 동일한 개념
- 스키마(schema)를 복제한 후 샤드키를 기준으로 데이터를 나누는 것을 말한다.
- 즉, 스키마(schema)가 같은 데이터를 두 개 이상의 테이블에 나누어 저장하는 것을 말한다.
특징
- 퍼포먼스, 가용성을 위해 key 기반으로 여러 곳에 분산 저장한다.
- 일반적으로 분산 저장 기술에서 파티셔닝은 수평 분할을 의미한다.
- 보통 수평 분할을 한다고 했을 때는 하나의 데이터베이스 안에서 이루어지는 경우를 지칭한다.
- 일반적으로 수평 파티셔닝 방식을 대부분 사용한다.
예시
- 고객의 데이터베이스를 샤딩하기로 한다. - CustomerId를 샤드키로 사용하여 샤딩
- 0~10000번 고객의 정보는 하나의 샤드에 저장하고 10001 ~ 20000번 고객의 정보는 다른 샤드에 저장한다.
- 데이터 액세스 패턴과 저장 공간 이슈(로드의 적절한 분산, 데이터의 균등한 저장)를 고려하여 적절한 샤드키를 결정한다.
- 같은 주민 데이터를 처리하기 위해 스키마가 같은 ‘서현동 주민 테이블’과 ‘정자동 주민 테이블'을 사용하는 것을 말한다.
- 인덱스의 크기를 줄이고, 작업 동시성을 늘리기 위한 것이다.
장단점
- 장점
- 데이터의 개수를 기준으로 나누어 파티셔닝한다.
- 데이터의 개수가 작아지고 따라서 index의 개수도 작아지게 된다. 자연스럽게 성능은 향상된다.
- 단점
- 서버 간의 연결 과정이 많아진다.
- 데이터를 찾는 과정이 기존보다 복잡하기 때문에 latency가 증가하게 된다.
- 하나의 서버가 고장나게 되면 데이터의 무결성이 깨질 수 있다.
2. 수직(vertical) 파티셔닝

테이블의 일부 열을 빼내는 형태로 분할한다.
개념
- 모든 컬럼들 중 특정 컬럼들을 쪼개서 따로 저장하는 형태를 의미한다.
- 스키마(schema)를 나누고 데이터가 그것을 따라 옮겨가는 것을 말한다.
- 하나의 엔티티를 2개 이상으로 분리하는 작업이다.
특징
- 관계형 DB에서 제3정규화와 같은 개념으로 접근하면 이해하기 쉽다.
- 하지만 수직 파티셔닝은 이미 정규화된 데이터를 분리하는 과정이다.
예시
- 한 고객은 하나의 청구 주소를 가지고 있을 수 있다. 그러나 데이터의 유연성을 위해 다른 데이터베이스로 정보를 이동하거나 보안의 이슈 등을 이유로 CustomerId를 참조하도록 하고 청구 주소 정보를 다른 테이블로 분리할 수 있다.
장단점
- 장점
- 자주 사용하는 컬럼 등을 분리시켜 성능을 향상시킬 수 있다. (특정 컬럼만을 고속 스캔할 때 유용)
- 한 테이블을 SELECT하면 결국 모든 컬럼을 메모리에 올리게 되므로 필요없는 컬럼까지 올라가서 한번에 읽을 수 있는 ROW가 줄어든다. 이는 I/O 측면에서 봤을 때 필요한 컬럼만 올리면 훨씬 많은 수의 ROW를 메모리에 올릴 수 있으니 성능상의 이점이 있다.
- 같은 타입의 데이터가 저장되기 때문에 저장 시 데이터 압축률을 높일 수 있다.
- 단점
- 수평 파티셔닝과 동일
🌳 파티셔닝의 분할 기준
데이터베이스 관리 시스템은 분할에 대해 각종 기준(분할 기법)을 제공하고 있다. 분할은 ‘분할 키(partitioning key)’를 사용한다.

1. 범위 분할 (range partitioning)


-- Range 파티셔닝
create table 주문( 주문번호 number, 주문일자 varchar2(8), 고객id varchar2(5) )
partition by range(주문일자) (
partition p2009_q1 values less than('20090401')
, partition p2009_q2 values less than('20090701')
, partition p2009_q3 values less than('20091001')
, partition p2009_q4 values less than('20100101')
, partition p2010_q1 values less than('20100401')
, partition p9999_mx values less than( MAXVALUE )
);- 오라클 8버전부터 제공된 가장 기초적인 파티셔닝 방식.
- 분할 키 값이 범위 내에 있는지 여부로 구분한다.
- 위 이미지와 같이 파티셔닝 테이블에 값을 입력하면 각 레코드를 파티션 키 컬럼 값에 따라 분할 저장하고, 읽을 때도 검색 조건을 만족하는 파티션만 읽을 수 있어 이력성 데이터 조회 시 성능을 크게 향상시켜 준다.
- 연속적인 숫자나 날짜를 기준으로 파티셔닝한다. 일별, 월별, 분기별 등의 데이터에 적합하고 손 쉬운 관리 기법 제공에 따른 관리 시간을 단축할 수 있어 주로 순차적인 데이터를 관리하는 테이블에 많이 사용된다.
- 파티션 키로는 하나 이상의 컬럼을 지정할 수 있고, 최대 16개까지 허용된다.
- 보관 주기 정책에 따라 과거 데이터가 저장된 파티션만 백업하고 삭제하는 등 데이터관리 작업을 효율적이고 빠르게 수행할 수 있는 것도 큰 장점이다.
- DB관리자의 실수로 신규 파티션 생성을 빠뜨리면 월초 또는 연초에 데이터가 입력되지 않는 에러가 발생하므로, maxvalue 파티션을 반드시 생성해 두는 것이 좋다.
- 11g 부터는 Range 파티션을 생성할 때 interval 기준을 정의함으로써 정해진 간격으로 파티션이 자동추가 되도록 할 수 있다.
- 예) 우편 번호를 분할 키로 수평 분할 하는 경우
2. 목록 분할 (List partitioning)

create table 인터넷매물( 물건코드varchar2(5), 지역?류varchar2(4) )
partition by list(지역?류)
(partition p_지역1 values ('서울'),
partition p_지역2 values ('경기', '인천'),
partition p_지역3 values ('부산', '대구', '대전', '광주'),
partition p_기타values (DEFAULT) ) ;
- 리스트 파티셔닝은 특정 컬럼의 특정 값을 기준으로 파티셔닝을 하는 방식이다. (사용자에 의해 미리 정해진 그룹핑 기준에 따라 데이터를 분할 저장하는 방식) - 단일 컬럼으로만 파티션 키를 지정해야 한다.
- 순서와 상관없이 불연속적인 값의 목록으로써 결정된다.
- 리스트 파티션에도 default 파티션을 생성해 두어야 안전하다.
- 특정 파티션에 저장 될 데이터에 대한 명시적 제어가 가능하며 주로 이질적인 값이 많지 않고 분포도가 비슷하고 대소문자를 구분하는데 허용문자 외 다른문자 입력 시 에러가 발생한다.
- 예) Country 라는 컬럼의 값이 Iceland , Norway , Sweden , Finland , Denmark 중 하나에 있는 행을 빼낼 때 북유럽 국가 파티션을 구축 할 수 있다.
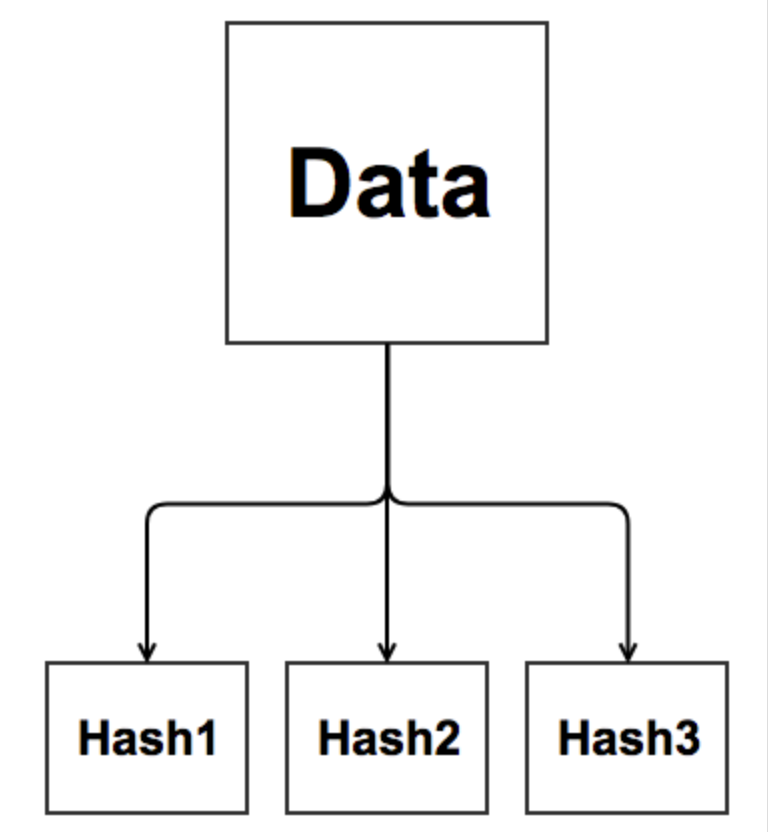
3. 해시 분할 (Hash partitioning)
- 예시 코드
SQL> create table t_hash1
2 (c1 number, c2 varchar2(10))
3 partition by hash (c1)
4 (partition p1 tablespace users,
5 partition p2 tablespace users);
테이블이 생성되었습니다.
SQL> create index t_hash1_idx on t_hash1(c1) local;
인덱스가 생성되었습니다.
SQL> select index_name, status
2 from dba_ind_partitions
3 where index_name = 'T_HASH1_IDX';
INDEX_NAME STATUS
------------------------------ --------
T_HASH1_IDX USABLE
T_HASH1_IDX USABLE
SQL> insert into t_hash1
2 select level, 'a' from dual connect by level<=1000;
1000 개의 행이 만들어졌습니다.
SQL> commit;
SQL> select index_name, status
2 from dba_ind_partitions
3 where index_name = 'T_HASH1_IDX';
INDEX_NAME STATUS
------------------------------ --------
T_HASH1_IDX USABLE
T_HASH1_IDX USABLE
SQL> alter table t_hash1
2 add partition p3 tablespace users;
테이블이 변경되었습니다.
SQL> select table_name, tablespace_name from dba_tab_partitions
2 where table_name = 'T_HASH1';
TABLE_NAME TABLESPACE_NAME
------------------------------ ------------------------------
T_HASH1 USERS
T_HASH1 USERS
T_HASH1 USERS
SQL> alter table t_hash1
2 add partition p3 tablespace users;
테이블이 변경되었습니다.
SQL> select table_name, partition_name from dba_tab_partitions
2 where table_name = 'T_HASH1';
TABLE_NAME PARTITION_NAME
------------------------------ ------------------------------
T_HASH1 P1
T_HASH1 P2
T_HASH1 P3
SQL> select index_name, status
2 from dba_ind_partitions
3 where index_name = 'T_HASH1_IDX';
INDEX_NAME STATUS
------------------------------ --------
T_HASH1_IDX UNUSABLE
T_HASH1_IDX USABLE
T_HASH1_IDX UNUSABLE
SQL> alter table t_hash1
2 add partition p4 tablespace users;
테이블이 변경되었습니다.
SQL> select index_name, status
2 from dba_ind_partitions
3 where index_name = 'T_HASH1_IDX';
INDEX_NAME STATUS
------------------------------ --------
T_HASH1_IDX UNUSABLE
T_HASH1_IDX UNUSABLE
T_HASH1_IDX UNUSABLE
T_HASH1_IDX UNUSABLE- 특정 컬럼 값에 해시 함수를 적용하여 분할하는 방식. (파티션 키에 해시함수를 적용한 결과 값이 같은 레코드를 같은 파티션 세그먼트에 저장)
- 데이터의 관리보다는 성능향상에 목적을 둠.
- 레인지 파티셔닝은 각 범위에 따라 데이터의 양이 일정하지 않아 분포도가 일정하지 않은 단점이 있지만, 해시 파티셔닝은 이러한 단점을 보완하여 일정한 분포도를 가진 파티션으로 나누고, 균등한 분포도를 가질 수 있도록 조율하여 병렬 프로세싱으로 성능을 높인다. 실제로 분포도를 정의하기 어려운 테이블을 파티셔닝 할 때 많이 이용(데이터가 얼마나 고르게 분산될 수 있느냐가 가장 중요한 관심사항이다.)
- 해시 파티셔닝 할 때 특히 데이터 분포를 신중히 고려해야 하는데, 사용자가 직접 파티션 기준을 정하는 Range, 리스트 파티셔닝과 다르게 해시 파티셔닝은 파티션 개수만 사용자가 결정하고 데이터를 분사시키는 해싱 알고리즘은 오라클에 으해 결정되기 때문이다.
- 파티션 키를 잘못 선정하면 데이터가 고르게 분산되지 않아 파티셔닝의 이점이 사라질 수도 있다.
- 해시 파티셔닝으로 구분된 파티션들은 동일한 논리, 물리적 속성을 가진다.
- 레인지 파티션과 달리 각 파티션에 지정된 값들을 데이터베이스 관리 시스템이 결정하므로 각 파티션에 어떤 값들이 들어있는지 알 수 없다.
- 검색할 때는 조건절 비교값에 해시 함수를 적용해 읽어야 할 파티션을 결정하며, 해시 알고리즘 특성상 "=" 조건 또는 "In-List" 조건으로 검색할 때만 파티션 Pruning이 작동한다.
- 오라클은, 특정 파티션에 데이터가 물리지 않도록 하려면 파티션 개수를 2의 제곱으로 설정할 것을 권고한다.
- Linear hashing Algorithm 을 사용하기 때문. Linear Hashing Alogorithm의 주소 확장방법은 한번에 모든 버킷을 분할하지 않고 첫 번째 버킷부터 분할해 가면서 마지막 버킷 분할이 끝나면 처음 버킷 에서부터 다시 시작하는 싸이클 방식 .
- 예) 4개의 파티션으로 분할하는 경우 해시 함수는 0-3의 정수를 돌려준다.
사용 목적
- 병렬 쿼리 성능 향상 : 데이터가 모든 파티션에 고르게 분산돼 있다면 더구나 각 파티션이 서로 다른 디바이스에 저장돼 있다면 병렬 I/O 성능을 극대화 할 수 있다.
- DML 경합 분산
- 대용량 테이블이나 인덱스에 발생하는 경합을 줄일 목적으로 해시 파티셔닝 사용
- 데이터가 입력되는 테이블 블록에도 경합이 발생할 수 있지만, 그보다는 입력할 블록을 할당받기 위한 Freelist 조회 때문에 세그먼트 헤더 블록에 대한 경합이 발생 할 때 해시 파티셔닝 하면 헤더 블록에 대한 경합을 줄일 수 있다.
- Right Growing 인덱스도 자주 경합 지점이 되곤 하는데, 맨 우측 끝 블록에만 값이 입력되는 특징때문이므로 이때 인덱스를 해시 파티셔닝함으로써 경합 발생 가능성을 낮출 수 있다.
4. 결합 분할 (composite partitioning)
- 결합 파티셔닝을 구성하면 서브 파티션마다 세그먼트를 하나씩 할당하고 서브 파티션 단위로 데이터를 저장한다.
- 주 파티션 키에 따라 1차적으로 데이터를 분배하고, 서브 파티션 키에 따라 최종적으로 저장할 위치를 결정한다.
Range + 해시 결합 파티셔닝

create table 주문( 주문번호number, 주문일자varchar2(8), 고객id varchar2(5) )
partition by range(주문일자)
subpartition by hash(고객id) subpartitions 8
( partition p2009_q1 values less than('20090401'),
partition p2009_q2 values less than('20090701'),
partition p2009_q3 values less than('20091001'),
partition p2009_q4 values less than('20100101'),
partition p2010_q1 values less than('20100401'),
partition p9999_mx values less than( MAXVALUE ));Range + 리스트 결합 파티셔닝

create table 판매 ( 판매점 varchar2(10), 판매일자 varchar2(8) )
partition by range(판매일자)
subpartition by list(판매점)
subpartition template
( subpartition lst_01 values ('강남지점', '강북지점', '강서지점', '강동지점')
, subpartition lst_02 values ('부산지점', '대전지점')
, subpartition lst_03 values ('인천지점', '제주지점', '의정부지점')
, subpartition lst_99 values ( DEFAULT ) )
( partition p2009_q1 values less than('20090401')
, partition p2009_q2 values less than('20090701')
, partition p2009_q3 values less than('20091001')
, partition p2009_q4 values less than('20100101') );
- 기타 결합 파티셔닝
- Range-Range
- 리스트-해시
- 리스트-리스트
- 리스트-Range
Sharding (샤딩)
🌳 샤딩이란?
샤딩의 종류는 데이터베이스 샤딩, 네트워크 샤딩, 트랜잭션 샤딩, 스테이트 샤딩 등이 있는데, 데이터베이스 샤딩만 다룰 예정.
샤딩(sharding)은 수평 파티셔닝(horizontal partitioning)과 같은 개념 (큰 데이터를 여러 서브셋으로 나누어 저장)
- 샤딩 : 하나의 큰 데이터를 여러 서브셋으로 나누어 여러 인스턴스에 나누어 저장 (DB서버를 분할)
- 수평 파티셔닝 : 하나의 큰 데이터를 여러 서브셋으로 나누고 하나의 인스턴스를 여러 테이블로 나누어 저장 (동일한 DB 서버 내에서 테이블을 분할)
샤딩은 하나의 거대한 데이터베이스나 네트워크 시스템을 여러 개의 작은 조각으로 나누어 분산 저장하여 관리하는 것을 말한다.
이는 단일의 데이터를 다수의 데이터베이스로 쪼개어 나누는 걸 말하는데, 단일의 데이터베이스에서 저장하기 너무 클 때 사용하여 데이터를 구간별로 쪼개어 나눔으로써 노드에 무겁게 가지고 있던 데이터를 빠르게 검증할 수 있어 빠른 트랜잭션 속도를 향상시킬 수 있다.
샤딩을 통해 나누어진 블록들의 구간(epoch)을 샤드(shard)라고 부른다.
주로 애플리케이션 레벨에서 실행됨. (어떤 데이터베이스 관리 시스템은 내장된 샤딩 능력이 있어서 데이터베이스 레벨에서 바로 사용할 수도 있다.)
🌳 샤딩 적용 전 고려사항
샤딩을 적용하면 프로그래밍, 운영적인 복잡도는 더 높아진다.
→ 가능하면 샤딩을 피하거나 지연시킬 수 있는 방법을 찾는 것이 우선되어야 한다.
- 서버 확장 : 대부분의 상황에서 더 많은 자원을 가진 머신으로 데이터베이스를 scaling up 하는 것은 sharding에 비해 공수가 적게 든다. replica를 만드는 것과 같이 서버를 업그레이드하는 것은 비용이 더 든다. 따라서 업그레이드가 베스트 옵션이라면 리사이징을 거쳐야할 것이다.
- scale-in : 하드웨어 스펙이 더 좋은 컴퓨터를 사용
- read 부하가 크다면 : cache나 데이터베이스의 replication을 적용하는 것도 하나의 방법
- 테이블의 일부 컬럼만 자주 사용한다면
- 수직 파티셔닝도 하나의 방법.
- Data를 Hot, Warm, Cold Data로 분리 → 참고 링크
Database Replication이란?
- 2개 이상의 DBMS를 Master와 Slave로 나누어 동일한 데이터를 저장한다.
- Master DB는 Insert, Update, Delete의 기능을 수행하고, Slave DB에 실제 데이터를 복사한다.
- Slave DB는 시간이 오래걸리는 Select문의 기능을 수행하여 전체적인 Select문 성능을 향상시킨다.
🌳 샤딩에 필요한 원리
- 분산된 데이터베이스에서 데이터를 어떻게 Read할 것인가?
- 분산된 데이터베이스에 데이터를 어떻게 잘 분산시켜서 저장할 것인가? 분산이 잘 되지 않고, 한 쪽으로 데이터가 몰리게 되면 자연스럽게 핫스팟이 되어 성능이 느려지게 됨 → 균일한 분산이 주요 목표
🌳 샤딩 방법
Shard Key를 어떻게 정의하느냐에 따라 데이터를 효율적으로 분산시키는 것이 결정됨.
1. Algorithm Sharding
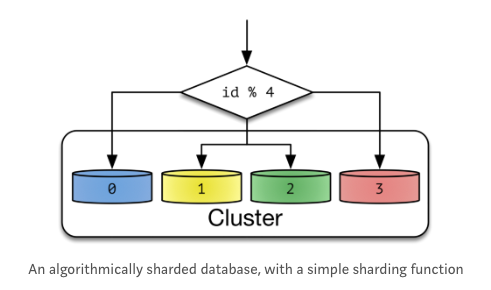
- Shard key : 데이터베이스 id를 해싱하여 결정 (해시 크기는 클러스터 안에 있는 노드 개수로 정함. hash(key) % NUM_DB 같은 방식)
- 장점 : 같은 값을 가지는 key-value 데이터베이스에 적합
- 단점 :
- 클러스터를 포함하는 Node 갯수가 변하게 되면 Resharding이 필요하다
- hash key로 분산되기 때문에 공간에 대한 효율이 부족하다. 예시) 짝수번째 노드에 큰 크기의 데이터만 들어감
2. Dynamic Sharding

- 클라이언트는 Locator Service에 접근하여 Shard key를 얻는다.
- 장점 : 클러스터가 포함하는 Node 갯수가 변하면 Shard key를 추가하기만 하면 된다. → 확장에 유연하게 대처 가능
- 단점 :
- data relocation 시에는 Locator Service의 shard key 테이블도 일치시켜야 한다. Locator에 의존할 수 밖에 없는 구조이다.
- 예시)
- HDFS : Name Node
- MongoDB : ConfigServer
3. Entity Group

- hash sharding과 dynamic sharding은 key-value 형태를 지원하기 위해 나온 방식 → key-value가 아닌 다양한 객체들로 구성하는 방식 : entity group
- RDBMS의 join, index, transaction을 사용하여 복잡도를 줄이는 방식과 유사
- 동일한 파티션에 관련있는 엔티티를 저장하여 단일 파티션 안에서 추가 기능을 제공하는 방식 (하나의 샤드에서 강한 응집도)
- 장점 :
- 하나의 물리적인 Shard에 쿼리를 진행하면 효율적
- 사용자의 증가에 따른 확장성이 좋음
- 단점
- 특정 파티션 간 쿼리가 자주 요구되는 경우가 있음
- cross-partition 쿼리는 single partition 쿼리보다 consistency의 보장과 성능을 잃음
참고자료
- http://wiki.gurubee.net/pages/viewpage.action?pageId=3899999
- https://gmlwjd9405.github.io/2018/09/24/db-partitioning.html
- http://wiki.hash.kr/index.php/파티셔닝
- http://wiki.gurubee.net/pages/viewpage.action?pageId=26742648
- http://www.gurubee.net/lecture/1906
- http://theeye.pe.kr/archives/1917
- https://brocess.tistory.com/205
- https://nesoy.github.io/articles/2018-05/Database-Shard
- https://sophia2730.tistory.com/entry/Databases-Database-Sharding샤딩
- https://galid1.tistory.com/797#:~:text=%EC%83%A4%EB%94%A9%2C%20%ED%8C%8C%ED%8B%B0%EC%85%94%EB%8B%9D(%EC%88%98%ED%8F%89)%20%EC%B0%A8%EC%9D%B4,%EB%82%98%EB%88%84%EC%96%B4%20%EC%A0%80%EC%9E%A5%ED%95%98%EB%8A%94%20%EA%B2%83%EC%9D%84%20%EB%A7%90%ED%95%A9%EB%8B%88%EB%8B%A4
'데이터베이스' 카테고리의 다른 글
| [데이터베이스] 복합 인덱스 순서는 중요할까? (0) | 2024.03.01 |
|---|
